
Structure of Tests-As-Specifications




| A big part of our thesis is that TDD is not really a testing activity, but rather a specifying activity that generates tests as a very useful side effect. For TDD to be a sustainable process, it is important to understand the various implications of this distinction. [1] [TestClass] This test is simple because the behavior is simple. But this is really not great as a specification. [TestClass] // Trigger // Verify Here we have included comments to make it clear that the three different aspect of this behavioral specification are now separate and distinct from each other. The "need" for comments always seems like a smell, doesn't it? It means we can still make this better.
// Setup Perhaps. We have reasons for preferring our version, which we'll set aside for its own discussion. [TestClass] // Trigger private MathUtils GetArithmeticMeanCalculator() Now, no matter how many test methods on this test class needed to access this arithmetic mean behavior (for different scenarios), a change in terms of how you access the behavior would only involve the modification of the single "helper" method that is providing the object for all of them. [TestClass] // Trigger private double TriggerArithmeticMeanCalculator(MathUtils mathUtils, private MathUtils GetArithmeticMeanCalculator() Now if we change the ArithmeticMean() method to take a container rather than discrete parameters, or whatever, then we only change this private helper method and not all the various specification-tests that show the behavior with more parameters, etc... [TestClass] // Trigger private double TriggerArithmeticMeanCalculation( private MathUtils GetArithmeticMeanCalculator() We have moved the call GetArithmeticMeanCalculator() to the Trigger, and expectedMean to the Verification [3]. Also we changed the notion of "trigger the calculator" to "trigger the calculation". Now, remember the original specification? |
Specifying The Negative in TDD
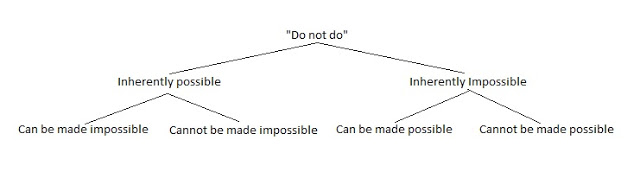
| One of the issues that frequently comes up is "how do I write a test about a behavior that the system is specified not to have?" It's an interesting question given the nature of unit tests. Let's examine it. The Decision Tree of Negatives When it comes to behaviors that the system should not have, there are different ways that this can be specified and ensured for the future:
Inherently Impossible Some things are inherently impossible, depending on the technology being used. For example you cannot write to read-only memory. This is in the nature of the memory and thus does not require a specification (nor a test, since that would be a test that could never fail). In languages like C# and Java, there exists the concept of “private”, and we know that an attempt to read or write a private value from outside a class will not compile and so will never exist in the executable system. Some things are inherently impossible and cannot be made possible even accidentally. Read-only memory cannot be made writable. However other things which are impossible by nature can be made possible if desired. A good example of this is an immutable object. Let's say there exists in our system a SaleAmount class that represents an amount of money for a given retail sale in an online environment. Such a class might exist in order to restrict, validate, or perfect the data it holds. In this case, however, there is a customer requirement that the value held must be immutable, for reasons of security and consistency in their transactions. This brings up the question "how do I specify in a test that you cannot change the value?" Developers will sometimes suggest two different ideas:
The problem with option #1 is that this is not what the requirement says, it is not what was wanted. The specification should be "you cannot change the value" not "if you change the value, thing x will happen." So here, the developer is creating his own specification and ignoring the actual requirements. The problem with option #2 is twofold: First, reflection is typically a very sluggish thing and in TDD we want our tests to be extremely fast so that we can run them frequently without this slowing down our process. But even if we overcame that somehow, what would we have the test look for? SetValue()? PutValue()? ChangeValue()? AlterValue()? The possibilities are vast and the cost of fully verifying immutability, in this case, would be enormous compared to the value. The key to solving this is in reminding ourselves once again that TDD is not initially about testing but creating a specification. Developers have always worked from some form of specification it's just that the form was usually some kind of document. So think about the traditional specification, the one you're likely more familiar with. Ask yourself this: Does a specification indicate everything the system does not do? Obviously not, for this would create a document of infinite length. Every system does a finite set of things, and then there is an infinite set of things it does not do. For example, here is an acceptance test for the positive requirement [2]: Given: A SaleAmount S with value V This could be made into an executable specification by the following simple test: [TestClass] var retrievedValue = testDollar.GetValue(); Assert.AreEqual(retrievedValue, initialValue); Which would drive the entity and its behavior into existence: public class SaleAmount public double GetValue() Ask yourself the following question: If we were using the TDD process to create this SaleAmount object, and if the object had a method allowing the value to be changed (SetValue() or whatever), how would it have gotten there? Where is the test that drove that mechanism into existence? It's not there because there is a specific requirement that it not be there. In TDD we never add code to the system without having a failing test first, and we only add the code that is needed to make the test pass, and nothing more. Put another way, if a developer on our team added a method that allowed such a change, and did not have a failing test written first, then he would be ignoring the rules of TDD and would be creating a bug as a result. TDD does not work if you don't do it. We don't know of any process that does. And if we think back to the concept of a specification there is an implicit rule here, which basically has two parts.
If it is a behavior nonetheless it is a defect. We don’t have a test that shows the value being changed, so it cannot be. But this does not mean we have a “test for immutability.” Anything that comes from the customer must be retained; we never want to lose that knowledge. So if we think of this requirement in terms of acceptance testing we could express it using the ATDD nomenclature: Given: A SaleAmount S with value V exists in the system There is no “When” in this case because this is a requirement that is always true, it is not based on system state. But this, of course, implies a strongly-typed, compiled language with access-control idioms (like making things "private" and so forth). What if your technology does not provide this? What if it is an interpreted language, or one with no enforcement mechanism to prevent access to internal variables? The first answer is: You have to ask the customer. You have to tell them that you cannot do precisely what they are asking for, and consider other alternatives in that investigation. It may well be that we are using the wrong technology. The second answer is that there will be some occasions where the only way you can ensure that an illegal or unwanted behavior is not added to a system accidentally is through static analysis (a traditional code review, or perhaps a code analysis tool). This is still “a test” but one that either cannot or should not be automated in all cases. On the other hand, sometimes we can make an inherently possible thing impossible by adding behaviors. Such behaviors must, of course, be test driven. Let's add a requirement to our SaleAmount class. If the context of this object was, say, an online book store, the customer might have a maximum amount of money that he allows to be entered into a transaction. We used a double-precision number [3] to hold the value in SaleAmount. A double can hold an incredibly large value inherently. In .net, for example, it can hold a value as high as 1.7976931348623157E+308 [4]. It does not seem credible that any purchase made at our customer's site could total up to something like that! So the requirement is: Any SaleAmount object that is instantiated with a value greater than the customer's maximum credible value should raise a visible alarm, because this probably means the system is being hacked or has a very serious calculation bug. As developers, we know a good way to raise an alarm is to throw an exception. We can do that, but we also capture the customer's view of what the maximum credible value is, so we specify it. Let's say he says "nothing over $1,000.00 makes any sense". But... how much "over"? A dollar? A cent? We have to ask, of course. Let's say the customer says "one cent". In TDD everything must be specified, all customer rules, behaviors, values, everything. So we start with this: Given: The system We also have to capture the tolerance in its own specification: Given: The System These tests establish bits of domain-specific language that can then be used in any number of other specifications (we won’t have to repeatedly define them whenever we make comparisons). [TestMethod] [TestMethod] In order to get these to pass we drive the Maximum and the Tolerance into the system. Given: Value S greater than or equal to Maximum + Tolerance [TestMethod] try But now the question is, what code do we write to make this test pass? The temptation would be to add something like this to the constructor of SaleAmount: But this is a bit of a mistake. Remember, it's not just "add no code without a failing test", it is "add only the needed code to make the failing test pass." Your spec is supposed to be your pal. He's supposed to be there at your elbow saying "don't worry. I won't let you make a mistake. I won't let you write the wrong code, I promise." He's not just your pal, he's your best pal. Here, however, the spec is just a mediocre friend because he will let you write the wrong code and say nothing about it. He’ll let you get in your car when you are in no condition to drive. He'll let you do this, and let it pass: throw new SaleAmountValueTooLargeException(); There is no conditional. We’re just throwing the exception all the time. That's wrong, obviously. This behavior has a boundary (as we discussed in our blog about test categories) and every boundary has two sides. We need a little more in specification. We need something like this: try { Now the "anAmount => MAXIMUM + TOLERANCE" part must be added to the production code or your best buddy will let you know you're blowing it. Friends don’t let friends implement incorrectly.
|
TDD and the "6 Do's and 8 Skills" of Software Development: Pt. 1
| This post is not about TDD per se, but rather a context in which TDD can demonstrate its place in and contribution to the value stream. This context has to do with the 6 things that we must accomplish (do) and the 8 skills that the team must have in order to accomplish them. We'll describe each "do", noting where and if TDD has an impact, and then do the same thing with the skills. 6 Dos:
8 Skills:
Everything the team does must be traceable back to business value. This means “the right thing” is the thing that has been chosen by the business to be the next most important thing, in terms of business value, that we should work on. TDD has no contribution to make to this. Our assumption is that this decision has been made, and made correctly before we begin our work. How the business makes this decision is out of scope for us, and if they make the wrong one we will certainly build the wrong thing. This is an issue of product portfolio management and business prioritization, and we do not mean to minimize its importance; it is crucial. But it’s not a TDD activity. It is the responsibility of project/product management. An analogy: As a restaurant owner, the boss has determined that the next thing that should be added to the menu is strawberry cheesecake. He made this decision based on customer surveys, or the success of his competitors at selling this particular dessert, or some other form of market research that tells him this added item will sell well and increase customer satisfaction ratings. It will have great business value and, in his determination, is the most valuable thing to have the culinary staff work on. DO THE THING RIGHT One major source of mistakes is misunderstanding. Communication is an extremely tricky thing, and there can be extremely subtle differences in meaning with even the simplest of words. “Clip” means to attach (clip one thing to another) and to remove (clipping coupons). A joke we like: My wife sent me to the store and said “please get a gallon of milk -- if they have eggs get six.” So I came back with 6 gallons of milk. When she asked why I did that, I replied “they had eggs.” The best way we know to ferret out the hidden assumptions, different uses of terms, different understanding, missing information, and the all-important “why” of a requirement (which is so often simply missing) is by engaging in a richly communicative collaboration involving developers, testers, and businesspeople. The process of writing acceptance tests provides an excellent framework for this collaboration, and is the responsibility of everyone in the organization. The analogy, continued: You work as a chef in the restaurant, and the owner has told you to add strawberry cheesecake to the menu. You prepare a graham-cracker crust, and a standard cheesecake base to which you add strawberry syrup as a flavoring. You finish the dish and invite your boss to try it. He says “I did not ask for strawberry flavored cheesecake, I asked for a strawberry cheesecake. Cheesecake with strawberry.” So you try again, this time making a plain cheesecake base and adding chopped up strawberries, stirring them in. The boss stops by to sample the product and says “no, no, not strawberries in the cake, I meant on the cake.” So you try another version where the plain cheesecake is topped by sliced strawberries. Again the boss in unhappy with the result. “Not strawberries, strawberry. As in a strawberry topping.” What he wanted was a cheesecake topped with strawberry preserves, which he has always thought of as “strawberry cheesecake.” All this waste and delay could have been avoided if the requirements had been communicated with more detail and accuracy. DO IT EFFICIENTLY For most organizations the primary costs of developing software are the time spent by developers and testers doing their work, and the effect of any delays caused by errors in the development process. Anything that wastes time or delays value must be rooted out and corrected. TDD has a major role to play here.
Software must be able to change if it is to remain valuable, because its value comes from its ability to meet a need of an organization or individual. Since these needs change, software must change. Changing software means doing new work, and this is usually done in the context of existing work that was already completed. One of the concerns that arises when this is done is: will the new work damage the existing system? When adding a new feature, for example, we need to guard against introducing bugs in the code that existed before we started our work. TDD has a significant role here, because all of our work proceeds from tests and thus we have test coverage protecting of our code from accidental changes. Furthermore, this test coverage is known to be meaningful because of how it was achieved. Test coverage that is added after a system is created is only guaranteed to execute the production code, but not to guarantee anything about the behavior that results from the execution. In TDD the coverage is created by writing tests that drive the creation of the behavior, so if they continue to pass we can be assured that the behavior remains the same. DO IT PREDICTABLY A big part of success in business is planning effectively, and this includes the notion of predictability. Every development initiative is either about creating something new, or changing something that already exists (and, in fact, you could say that creating something new is just a form of change: from nothing to something). One question we seek to answer when planning and prioritizing work is: how long will it take and how many resources will be required? Although we know we can never perfectly predict these things, we want to reduce the degree of error in our predictions. TDD has a role to play here:
The team must work in a way that can be sustained over the long haul. Part of this is avoiding overwork and rework, and making sure the pace of work is humane. Part of this is allowing time for the team to get appropriate training, and thus to "sharpen the saw" between major development efforts. Issues like these are the responsibility of management whether the team is practicing TDD or not. However, this work is called "Sustainable Test-Driven Development" for a reason. TDD itself can create sustainability problems if the maintaining the test suite presents an increasingly-significant burden for the team. Much of our focus overall has been and will continue to be avoiding this problem. In other words, TDD will not create sustainability unless you learn how to do it right. |
TDD Mark 3, part 2
| I realized recently that this had been written, but never published. Part 1 was, but never this second part. Not sure how that happened. Maybe I needed a test. :) Anyway, here it is. Part three is still pending. -Scott-
|
TDD Mark 3 Introduced
| First of all, sorry for the long absence. Our training schedule has been wall-to-wall, and when one of us had a brief gap the other has always been busy. It has given us time to think, however. Long airplane rides and such. :) We're been playing around with an idea we're calling (for the moment) TDD Mark 3 (the notion that TDD is not about testing but rather about specification being TDD Mark 2). To give you an idea of what we're thinking, let's look at an example of TDD Mark 2 as we've been writing tests up to this point, and then refactor it to the TDD Mark 3 style. Mark 2 [TestClass] [TestMethod] uint insufficientFunds = minimalFunds - 1;
Naturally, there are many other tests that specify the various aspects of the Card's behavior, and together they turn the user's requirement into an executable specification. That's what Mark 2 is all about. Refactor to Mark 3 We should also acknowledge that the tests that we write are not "second class citizens". They require as much love and attention as the production code they specify. This means that after the test has been written we have an opportunity to refactor its design. This is done with respect to specific changes that may be required in the code. These can come from two sources - changing requirements and changing the domain model to reflect changing responsibilities. Changing requirement could comprise raising the minimal limit or creating a graded discount structure. Changing the domain comprises adding or removing classes or methods on classes. The customers new requirement is this: there are other ways to charge the user for on-board services. It turns out that guests often do not carry the card with them (to the pool, for example) but would still like to purchase cute drinks with little pink umbrellas. To enable that, a biometric system was installed where the guest can charge the drink to his card by swiping their finger over a fingerprint scanner incorporated into the card reader held by the server. This means that the model we created where the Card was the central object needs to be refined, and an Account class introduced. The Card is just one way if interacting with the account. What affect will this have on our test? All reference to Card must be replaced with references to Account. Considering out test code there are two redundancies that we can identify: Card.MINIMAL_FUNDS and card.LoadFunds(). [TestClass] [TestMethod] uint insufficientFunds = minimalFunds - 1; We don't like redundancies in our tests any more than we like them in our production code. We extract the redundancies into methods:
[TestMethod] Card card; private void LoadFunds(uint funds) We can inline the MinimalFunds private function and get: [TestClass] [TestMethod] uint insufficientFunds = MinimalFunds() - 1; Card card; private void LoadFunds(uint funds) Wait! There's another redundancy above: try We are specifying the type of the exception twice...We'll deal with that redundancy in a bit, so we'll put it on the to-do list. In the meanwhile, back to the refactored tests. I do not like the name we gave the LoadFunds method, it's misleading. The customer not want the exception to be thrown every time the card is loaded with a small amount -- only on the initial load. So perhaps this is better: [TestMethod] uint insufficientFunds = MinimalFunds() - 1;
Note the fact that card's initialization was moved into the LoadInitialFunds method.
And where should the limit be defines? Account, and it will return the value in a method. Finally, we can make the changes in the test, but only because we left the two references to the exception in the test. [TestMethod] uint insufficientFunds = MinimalFunds() - 1;
Well, if you remember, the customer wanted the user to be notified if the amount is too small. Exceptions are just one way of doing it. So we can safely say that the specific exception is an implementation detail, and based on the role we want the public method to play - specification, we really need to get that implementation detail out of here. So, here's a question to our readers. How would you do it? Note that although we used C# right now, the refactoring principles are relevant to any language. So without dealing with the exception, yet, this is what the test code looks like. [TestClass] [TestMethod] uint insufficientFunds = MinimalFunds() - 1; private UInt MinimalFunds() { private void LoadFunds(uint funds) The public methods now essentially constitute an acceptance test. In fact, those familiar with acceptance testing frameworks like FIT would express what these unit test methods communicate in another form, like a table for example, and the private methods would be the fixtures written to connect the tests to the system's implementation. This does make the test class longer and more verbose, but it also makes it easier to read just the specification part, if that's all you are interested in. Also, when design changes are made later (lets say, for example, that we decide to build the Account in a factory, or store the minimal initial value in a configuration file) that only one private method will be effected by a given change, and none of the public methods at all (which makes sense, since the design has been altered but not the acceptance criteria). Mark 3 We also have a separation between the specification and implementation. We call these - different perspectives. And they allow us to focus on getting the requirement right, and then getting the design right. We can change the design without affective the requirement. This is a major piece of making TDD sustainable. As this allows us to change the system design without affecting the public tests which specify the behavior. So, the $1.000,0000 question is: "Why not write the tests that way to begin with?" To Be Continued....
|