
Magic Buttons and Code Coverage




| This will be a quickie. But sometimes good things come in small packages.
|
TDD and Design: Frameworks
| Increasingly, in modern software development, we create software using components that are provided as part of a language, framework, or other element of an overall development ecosystem. In test-driven development this can potentially cause difficulties because our code becomes dependent on components that we did not create, that may not be amenable to our testing approaches, and that the test cannot inherently control. That last part is particularly critical. In TDD, we want to create unique, isolated tests that fail for one specific reason and thus specify one narrowly-defined behavior of the system. Tests that involve multiple behaviors are hard to read (as a specification) and will have multiple reasons to fail. When a test fails, we want to know unequivocally why it failed so that we can efficiently address the issue. We write tests in TDD to specify the proper behavior of the system, allowing us to confidently create the right things. But they also, later, serve as tests to ensure that defects have not been introduced. In this second mode, what does the test actually test? A test will always test everything that is in scope which it does not control. If a test is to be narrowly focused on just one thing, then everything else that is in scope must be brought under the control of the test, otherwise it is testing those things as well. Let's roll the dice and look at an example: Most people are familiar with the game Yahtzee. Briefly, you roll five dice and try to make the best pattern you can. Examples are three of a kind, or numbers in a sequence (a "straight") and so forth, all the way up to a "yahzee" which means all five dice are the same. "Chance" means you have no pattern at all, just five unrelated numbers. public enum Result { CHANCE, ACES, TWOS, THREES, FOURS, PAIR, public class Yahtzee dice[1] = (char)rand.Next(6); // Logic to determine the best result and set myResult return myResult; The idea here is to roll five dice and have the game tell you what the best pattern is that you can make from the five random results that you got. The default is "Chance" unless something better can be made from the die rolls you got. What we would want to specify here is that the logic (which is commented out for brevity) would correctly identify various patterns of die rolls. If we rolled 4 5's, for example, it would identify it as Result.FOUROFAKIND even though it is also true that we have three of a kind. The problem is that Random is in scope... we are using it. But unless we bring it under the control of the test we are also testing Random, which is not what we want. Also, we cannot predict what Random will do. We could seed the Random class with a known value, but even so we are testing more than we wish to. How can we truly bring random under control? This same issue would exist in code that is dependent upon any component: a GPS module, the system clock, a network socket, etc... A Design Principle In seeking to ensure high-quality designs, we need standards or rubrics to apply to any proposed design. We want to check out thinking, to make sure we're not fooling ourselves or missing anything. One such rubric is this: When examining an entity (class, method, whatever) in our system we ask: is this entity aware of the framework, or aware of the application logic? If the answer is "both", then we seek some way to separate the two aspects of the entity from each other. If you examine the code above you'll see that this game entity is aware of the framework (how you create a use the Random class) and also the application logic (the rules of this particular game). This is a clue that we should reconsider the structure of our code. Note that this concern also impacts the testability of the code because, as we've already noted, the test does not want to be vulnerable to the Random component. We want the test to be solely concerned with the game logic. A Testing Adapter One way to bring the framework component under the control of the test is to wrap it in an adapter, and then mock the wrapper: class DieRoller public virtual char RollDie() { ..and then change the product code to use this class instead of using the framework element directly. For the test, we could mock this class and inject the mock instead of the adapter, bringing the die rolled in each case under the control of the test. One example: class MockDieRoller : DieRoller { public void setRoll(char aRoll) { public override char RollDie() { An Endo Test Creating an adapter class is a viable option when it comes to framework components, but it may seem like overkill in some cases. When the issue in question is very simple, as in our example, you could also control the dependency through a simple technique called "endo-testing." public class Yahtzee dice[1] = rollDie(); // Logic to determine the best result and set myResult return myResult; protected virtual char rollDie() { All we have done is extracted the use of the Random class into a local, protected virtual method. This is a very simple and quick refactor; virtually any decent IDE will do this for you. The test will look like this: [TestClass] private class TestableYahtzee : Yahtzee { protected override char RollDie() { Now the test can control what dice are rolled and conduct all the various scenarios to ensure that the rules of the game are adhered to. Also, we've satisfied our design principles by separating game logic and framework knowledge into two methods, rather than two classes.
[1] See our blogs and podcast on mocking for more details: https://www.projectmanagement.com/blog-post/68254/Mock-Objects--Part-2 https://www.projectmanagement.com/blog-post/68253/Mock-Objects--Part-3 |
TDD: Testing Behavior in Abstract Classes
| INTERFACES VS. ABSTRACT CLASSES Furthermore, many teams adopt the “I” naming convention for interfaces; namely that an interface’s name should start with a capital I, whereas other classes (including abstract classes) should not. The problem with this convention is that it creates design coupling. Client objects that contain references to service objects must be changed when a simple, concrete class must be changed to become an abstraction, if an interface is to be used to model it. Should client objects care whether a service is a concrete class, abstract class, or interface? No. This would seem to argue against this naming convention in the first place. But the real problem stems from the fact that the “interface” type is commonly used for two very different purposes: to create polymorphism and to mark a class as a valid participant in a framework process. For example, a class can implement “ISerializible”, not for casting purposes per se, but so it can be serialized by .Net or a similar framework. This may be a tangential issue to the class’ core responsibility. On the other hand, 10 different versions of a tax calculation algorithm implemented by 10 different tax calculation classes can all implement “ITaxCalc” so that they can be cast up and dealt with in the same way by various client classes. This would create polymorphism around the central responsibility of all the classes involved: calculating taxes. If we had started with a single algorithm, a concrete class called TaxCalc, and this was referred to across the system by that name, then when we evolve the system to support different algorithms and thus the class becomes an interface, then the type name would change (if the “I” convention is used) and all client code will have to be maintained.
Part of my argument is this: when many different classes have a conceptual relationship, such as the tax calculators mentioned above, then it is likely they will also contain some code in their implementation that is the same. This yields redundancy that creates maintenance problems when requirements due to tax laws and regulations change (for example). An abstract class can implement common functionality, whereas interfaces cannot. Even if a set of related classes contains no redundant implementation today, redundancies can emerge over time. Abstract classes make this problem easy to solve whenever it arises. Also, if I limit the use of interfaces to process flags, then the “I” convention is less of an issue. I do not create design coupling within my system if I use it, because, for example, “IComparable” is not my interface, it allows a collection of classes to be sorted by a framework. It belongs to that framework and is highly unlikely to be changed, due to the chaos this would create in everyone’s code if it were to be. In any case, I don’t control its name.
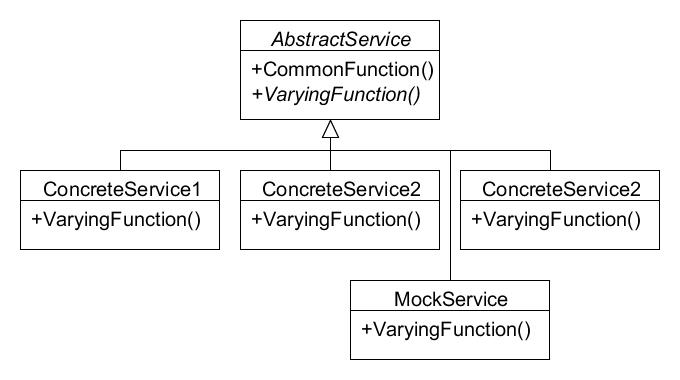
Here is a completely generic example:
Each “ConcreteService” version would have its own test, for each implementation version of the “VaryingFunction()” method. But how would one write a test for the “CommonFunction()” method if it were an instance method, and one cannot create a instance? Initially you might say “well, just pick any of the subclasses, create an instance of it and test the common function there, as they all have access to it.” The problem is that this creates coupling in the test to the concrete service class that you arbitrarily chose. If you happened to pick “ConcreteService1”, for instance, and later that class were to be retired/eliminated due to changing requirements, then the test of the common function would break even though that function is working fine. Similarly, if "ConcreteService1" at some point in the future were to be changed to override the "CommonFunction()" method, this will also break the test. We want tests that fail only for the reason we wrote them to.
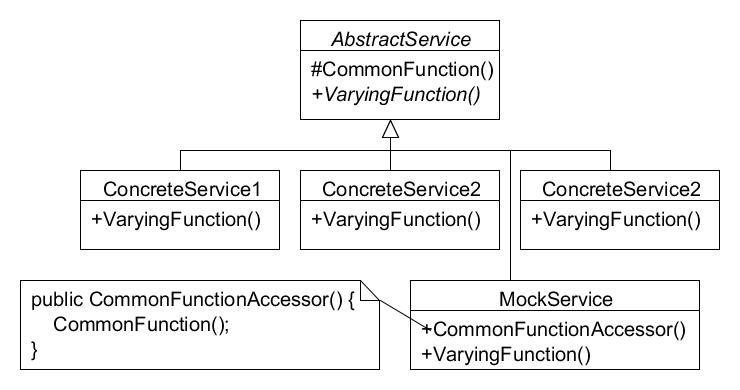
This mock, like any subclass, has access through inheritance to the common function, but unlike other subclasses the mock:
Another advantage of this approach is that it makes it easier to test base-class behavior that is not exposed to the system in general (not public).
This is a pattern, a “Testing Class Adapter”[2]. It works because the test will hold the “Mock Service” by its concrete type, not in an upcast, and thus this new accessor method, which is public, can be called to access the protected method in the base class. Again, this mock is not part of production, and thus does not break encapsulation in general, only for testing.
[2] For more on the Adapter Pattern see: |

Test-Driven Development in the Larger Context: Pt 4. Synergy
| Having established the differences between ATDD and UTDD, how are they the same? Why are they both called “TDD” collectively? Tests ensure a detailed and specific, shared understanding of behavior. If properly trained, those who create these tests will subject their knowledge to a rigorous and unforgiving standard; it is hard if not impossible to create a high-quality test about something you do not know enough about. It is also unwise to try and implement behavior before you have that understanding. TDD ensures that you have sufficient and correct understanding by placing tests in the primary position. This is equally true for acceptance tests as it is for unit tests, it's just that the audience for the conversation is different.. Tests capture knowledge that would otherwise be lost. Many organizations we encounter in our consulting practice have large complex legacy systems that no one understands very well. The people who designed and built them have often retired or moved on to other positions, and the highly valuable knowledge they possessed left with them. If tests are written to capture this knowledge (which, again, requires that those who write them are properly trained in this respect) then not only is this knowledge retained, but also its accuracy can be verified at any time in the future by simply executing the tests. This is true whether the tests are automated or not, but obviously the automation is a big advantage here. This leads us to view tests, when written up-front, as specifications. They hold the value that specifications hold, but add the ability to verify accuracy in the future. Furthermore, if any change to the system is required, TDD mandates that the tests are updated before the production code as part of the cadence of the work. This ensures that the changes are correct, and that the specification never becomes outdated. Only TDD can do this. Tests ensure quality design. As anyone can tell you who has tried to add tests after the fact to a legacy system, bad design is notoriously hard to test. If tests precede development, then design flaws are made clear early in the painful process of trying to test them. In other words, TDD will tell you early if your design is weak because the pain you’ll feel is a diagnostic tool, as all pain is. Adequate training in design (design patterns training for example)will ensure that the team understands what the design should be, and the tests will confirm when this has happened. Note that this is true whether tests are written or not; it is the point of view that accompanies testability that drives toward better design. In this respect the actual tests become an extremely useful side-product. That said, once it is determined how to test something, which ensures that it is indeed testable, then the truly difficult work is done. One might as well write the tests… What TDD does not do, neither in terms of ATDD nor UTDD, is replace traditional testing. The quality control/quality assurance process that has traditionally followed development is still needed as TDD will not test all aspects of the system, only those needed to create it. Usability, scalability, security, and so on still need to be ensured by traditional testing. What TDD does do is contribute some of the tests needed by QA, but certainly not all of them. There is another benefit to the adoption of TDD, one of healthy culture. In many organizations, developers view the testing effort as a source of either no news (the tests confirm the system is correct) or bad news (the tests point out flaws). Similarly, testers view the developers as a source of myriad problems they must detect and report. When TDD is adopted, developers have a clearer understanding of the benefits of testing from their perspective. Indeed, TDD can become a strongly-preferred way to work by developers because it leads to a kind of certainty and confidence that they are unaccustomed to, and crave. On the other hand, testers begin to see the development effort as a source of many of the tests that they, in the past, had to retrofit onto the system. This frees them up to add the more interesting, more sophisticated tests (that require their experience and knowledge) which otherwise often end up being cut from the schedule due to lack of time. This, of course, leads to better and more robust products overall. Driving development from tests initially seemed like an odd idea to most who heard of it. The truth is, it makes perfect sense. It’s always important to understand what you are going to build before you build it, and tests are a very good way to ensure that you do and that everyone is on the same page. But tests deliver more value than this; they can also be used to efficiently update the system, and to capture the knowledge that existed when the system was created, months, years, even decades in the future. They ensure that the value of the work done will be persistent value, and in complete alignment with the forces that make the business thrive. TDD helps everyone. |
Test-Driven Development in the Larger Context: Pt 3. Automation
| Both ATDD and UTDD are automatable. The difference has to do with the role of such automation, how critical and valuable it is, and when the organization should put resources into creating it. AUTOMATION ATDD ATDD’s value comes primarily from the deep collaboration it engenders, and the shared understanding that comes from this effort. The health of the organization in general, and specifically the degree to which development effort is aligned with business value will improve dramatically once the process is well understood and committed to by all. Training your teams in ATDD pays back in the short term. Excellent ATDD training pays back before the course is even over. Automating your acceptance test execution is worthwhile, but not an immediate requirement. An organization can start ATDD without any automation and still get profound value from the process itself. For many organizations automation is too tough a nut to crack at the beginning, but this should not dissuade anyone from adopting ATDD and making sure everyone knows how to do it properly. The automation can be added later if desired but even then, acceptance tests will not run particularly quickly. That is acceptable because they are not run very frequently, perhaps part of a nightly build. Also, it will likely not be at all clear, in the beginning, what form of automation should be used. There are many different ATDD automation tools and frameworks out there, and while any tool could be used to automate any form of expression, some tools are better than others given the nature of that expression. If a textual form, like Gherkin, is determined to be clearest and least ambiguous given the nature of the stakeholders involved, then an automation tool like Cucumber (Java) or Specflow (.Net) is a very natural and low-cost fit. If a different representation makes better sense, then another tool will be easier and cheaper to use. The automation tool should never dictate the way acceptance tests are expressed. It should follow. This may require the organization to invest in the effort to create its own tools or enhancements to existing tools. but this is a one-time cost that will return on the investment indefinitely. In ATDD the clarity and accuracy of the expression of value is paramount; the automation is beneficial and "nice to have." UTDD requires automation from the outset. It is not optional and, in fact, without automation UTDD could scarcely be recommended. Unit tests are run very frequently, often every few minutes, and thus if they are not efficient it will be far too expensive (in terms of time and effort) for the team to run them. Running a suite of unit tests should appear to cost nothing to the team; this is obviously not literally true, but that attitude should be reasonable. Thus, unit tests must be extremely fast, and many aspects of UTDD training should ensure that the developers know how to make them extremely painless to execute. They must know how to manage dependencies in the system, and how to craft tests in such a way that they execute in the least time possible, without sacrificing clarity. Since unit test are intimately connected to the system from the outset, most teams find that it makes sense to write them in the same programming language that the system itself is being written in. This means that the developers do not have to do any context-switching when moving back and forth between tests and production code, which they will do in a very tight loop. Unlike ATDD, the unit-testing automation framework must be an early decision in UTDD, as it will match/drive the technology used to create the system itself. One benefit of this is that the skills developers have acquired for one purpose are highly valuable for the other. This value flows in both directions: writing unit tests makes you a better developer, and writing production code makes you a better tester. Also, if writing automated unit tests is difficult or painful to the developers, this is nearly always a strong indicator of weakness in the product design. The details are beyond the scope of this article, but suffice it to say that bad design is notoriously hard to test, and bad design should be rooted out early and corrected before any effort is wasted on implementing it. |