Strategies for Capturing Quality Requirements
Categories:
agile,
architecture,
non-functional requirements,
requirements,
testing,
Scrum,
test strategy
Categories: agile, architecture, non-functional requirements, requirements, testing, Scrum, test strategy




|
Quality requirements, also known as non-functional requirements (NFRs), quality of service (QoS) or technical requirements, address issues such as reliability, availability, security, privacy, and many other quality issues. The following diagram, which overviews architectural views and concerns, provides a great source of quality requirement types (the list of concerns). Good sources for quality requirements include your enterprise architects and operations staff, although any stakeholder is a potential source for them. Figure 1. Architectural views and concerns.
Why Are Quality Requirements Important?Stakeholders will describe quality requirements at any time, but it’s particularly important to focus on them during your initial scoping efforts during Inception as you can see in the goal diagram below for Explore Initial Scope. Considering quality requirements early in the lifecycle is important because:
Capturing Quality RequirementsFigure 2 depicts the goal diagram for Explore Scope. As you can see, there are several strategies for exploring and potentially capturing quality requirements. Figure 2. The goal diagram for Explore Scope (click to enlarge).
Let’s explore the three strategies, which can be combined, for capturing quality requirements:
Of course a fourth option would be to not capture quality requirements at all. In theory this would work in very simple situations but it clearly runs a significant risk of the team building a solution that doesn’t meet the operational needs of the stakeholders. This is often a symptom of a teams only working with a small subset of their stakeholder types (e.g. only working with end users but not operations staff, senior managers, and so on). Related Resources |



New goal: Develop Initial Test Strategy
|
We have recently published a new Inception process goal, Develop Initial Test Strategy. The potential need for this goal was identified a little over a year ago by an organization that we were actively working with and since then we have worked with several other organizations where it was also clear that this process goal was needed. The basic idea is that during the Inception phase the team should consider developing an initial test strategy so as to identify how they will approach verification and validation. This includes thinking about how you intend to staff your team, organize your team, capture your plan, approach testing, approach development/programming, choose a platform for test environment(s) platform, choose a platform equivalency strategy, test non-functional requirements, automate test suites, obtain test data, automate builds, report defects, and govern your quality efforts. The goal diagram is depicted in Figure 1 and the update goals overview for Disciplined Agile Delivery (DAD) is shown in Figure 2. Figure 1. The goal diagram for Develop Initial Test Strategy.
Figure 2. The process goals diagram for DAD.
|


When Should You Assign Points to Defects?
| A common question that we get from teams who are new to agile is whether you should assign points (sizes) to defects. From a Disciplined Agile point of view we know that the answer will vary depending on the context of the situation, or in other words “it depends.” The really disciplined answer though is to say on what it depends, which is what we explore in this blog. Rod Bray, a senior agile coach and Disciplined Agile instructor, suggests this principle: Don’t reward people for shoddy work An implication of this is that if a team is injecting defects, they’re producing shoddy work, then it makes sense that their velocity suffers when they have to spend time fixing those defects. The decrease in velocity is a visible trigger to investigate, and address, the cause of the productivity loss. But what if the “shoddy work” wasn’t caused by your team? What if the “shoddy work” was previously acceptable to your stakeholders? Hmmm… sounds like the context of the situation counts in this case. The following flowchart works through common thinking around when to size a defect. Note that this is just our suggestion, your team could choose to do something different. Let’s work through common scenarios to understand whether defects should be sized or not. These scenarios are:
Do you size the repair of existing technical debt?The quick answer is sometimes. For the sake of discussion we’ll assume that this technical debt has existed for a long time, potentially years. From a purist point of view technical debt may be injected at any time (this is obviously true) and as a result may only be seconds old. In the case of technical debt that is very new, refer to the logic below. The key issue is whether fixing the defect is going to be a substantial effort. This of course is subjective. Is the work substantial if it’s less than an hour of effort? Several hours? Several days? Several weeks? This is a bar that your team will need to set. Something that will impact your schedule is likely to be substantial (and something your Product Owner is likely going to want to prioritize so that it can be planned for appropriately). Clearly a defect that takes several days or more to fix is substantial and one that takes less than an hour is likely not. Something that takes several hours or a day or so is likely something you need to think about.
Do you size defects injected and by found by the team?No, the exception being technical debt (see above). This falls under the principle of not rewarding the team for shoddy work.
Do you size defects found by independent testing?Some teams, particularly those working in regulatory environments or working in complex environments, may be supported by an independent test team. An overview of the independent testing strategy is presented below. With the exception of the defect being found in existing technical debt (see above), the defect should not be sized. Once again, the principle described earlier holds. Of course if you don’t have an independent test team supporting your team then obviously you can ignore this question.
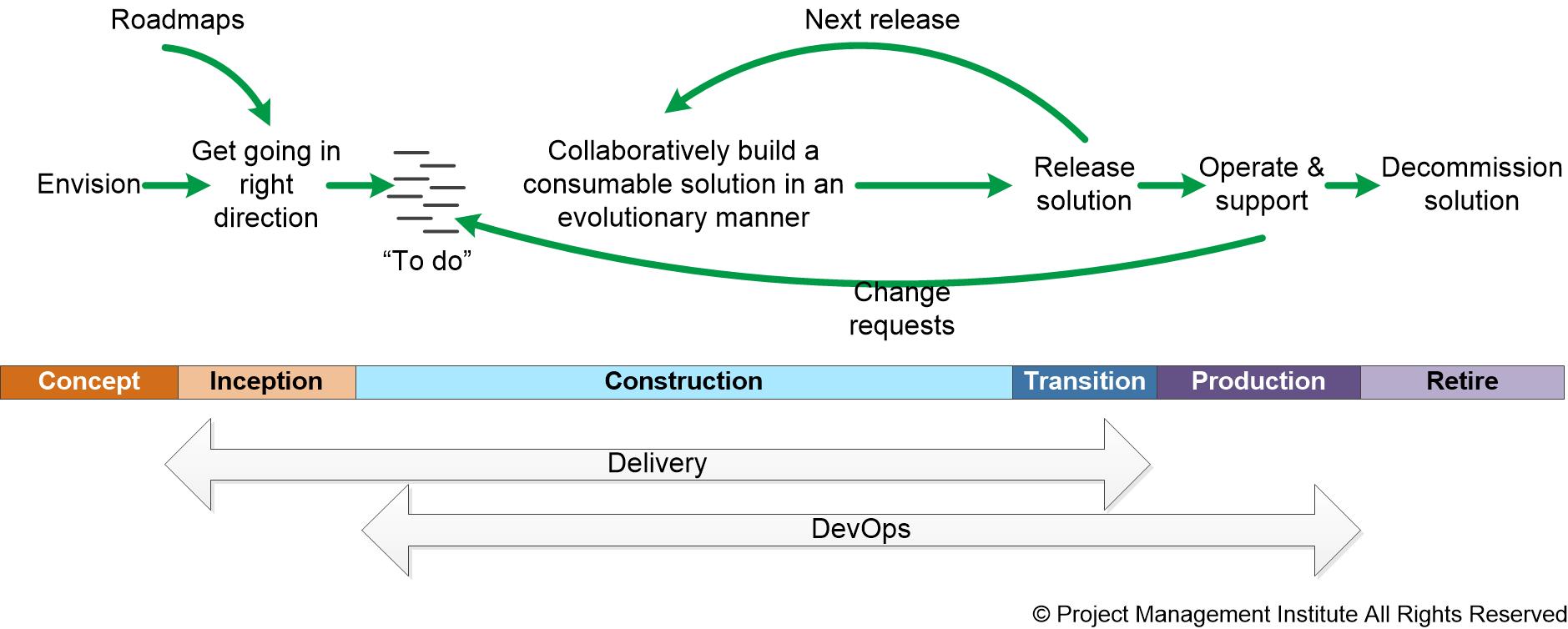
Do you size defects found in production?The answer is sometimes. As you can see in the high-level lifecycle diagram below, the DA toolkit explicitly recognizes that change requests are often identified by end users of an existing solution. These change requests are effectively new requirements that should be prioritized and worked on appropriately. Many organizations will choose to distinguish between two types of change requests, defects and enhancements, so that they may be treated differently. The issue is that defects are often tracked and, if the team is smart, they are analyzed to determine how they got past the team in the first place. Additionally you may find that defects and enhancement requests are charged for differently (a topic for a future blog).
If you don’t distinguish between defects and enhancement requests then there’s nothing to do, you simply treat the change request as a new requirement and size it like you normally would. But if you do distinguish between types then you need to think about it a bit. If the defect is found during a warranty period then it shouldn’t be charged for. Sometimes, particularly when work is being outsourced, there is a warranty period of several weeks or even months after something is released where the development team is expected to fix defects for free. In this case you likely wouldn’t size the work in line with the principle described earlier. Once you’re out of the warranty period then it’s likely you want to assign points to it: The functionality in question passed testing and was accepted by your stakeholders, so they in effect have taken responsibility for it. To summarize, the answer to the question “Should we assign points to a defect?” is “it depends.” In this blog we explored in detail why this is the case and described when and when you wouldn’t want to assign points. I’d like to thank Kristen Morton, Rod Bray, and Glen Little for their insights which they contributed to this blog. |


Independent Testing and Agile Teams
| The majority of testing, and in simple situations all of it, is performed by an agile delivery team itself. This is because we strive to have cross-functional “whole teams” that have the capability and accountability to perform the activities of solution delivery from beginning to end. For organizations new to agile this means that you embed testers on agile teams and for organizations experienced in agile that you’ve managed to motivate agile team members to gain testing skills over time (often via close collaboration with other people who already have those skills). This blog is organized into the follow topics:
Parallel Independent TestingThe whole team approach to development where agile teams test to the best of the ability is a great start, but it isn’t sufficient in some scaling situations. In these situations, described below, you need to consider instituting a parallel independent test team that performs some of the more difficult or expensive forms of testing. As you can see in Figure 1, the basic idea is that on a regular basis the development team makes their working build available to the independent test team. This may happen several times an iteration – we’ve seen teams do so at the end of each iteration, on a nightly basis, as part of their continuous deployment (CD) strategy. How often this occurs needs to be negotiated between the two teams. Figure 1. Independent testing with an agile team.
The goal of this independent testing effort is not to redo the confirmatory testing that is already being done by the development team, but instead to identify the defects that may have fallen through the cracks. The implication is that this independent test team does not need a detailed requirements speculation, although they may need updated release notes including a list of changes since the last time the development team sent them a build. Instead of testing against the specification, the independent testing effort typically focuses on:
Why Independent Testing?There are several reasons why you should consider independent testing:
Figure 2: Average cost of change curve.
Questionable Reasons to Adopt Independent TestingWe’ve run into a few rather poor excuses to justify independent testing over the years:
But That Isn’t Agile!Bullshit! Please excuse my language. Disciplined agile is pragmatic, going beyond the limited approach promoted by many agile purists. These purists will claim that you don’t need parallel independent testing, and in simple situations this is clearly true. The good news is that it’s incredibly easy to determine whether or not your independent testing effort is providing value: simply compare the likely impact of the defects/change stories being reported with the cost of doing the independent testing. In short, whole team testing works well for agile in the small, but for more complex systems and in some tactical scaling situations you need to be more sophisticated. |

Recovery Testing
|
by Danial Schwartz In Disciplined Agile Delivery (DAD), testing is so important we do it all the way through the lifecycle. One approach that your team will need to consider performing is recovery testing, which is used to see the ability of a system to handle faults. If a fault occurs, does the system keep working and does not stop? In case of a fault can the system recover within a specified period of time? In the event of a critical failure will damage such as physical, economical, health related, etc., result or not? Recovery testing constitutes of making the system fail; then the results of system recovery are observed. The efficiency of the system to return to normal and the time it takes to do so are examined. The disturbances which can result in failure and need to be checked vary from product to product and from industry to industry. Consider the healthcare industry and medical devices. When products are developed for the health care industry they have to be in strict accordance with FDA guidelines. They also have to adhere to the guidelines provided by the company for which the product is being made. When recovery tests are made they naturally have to comply with these strict rules. The tests require validation and so does the environment in which they are to be carried out. The Defense Industry consists of complex systems embedded within one another. The interlink of the systems requires recovery testing which takes into account how different systems affect one another. Since the industry has to deal with harsh environmental variables, these have to be replicated for recovery testing. Doing so is no easy task. Cloud applications are increasing in popularity. They are part of cloud systems. The cloud systems, in turn, are made up of commodity machines. This allows taking advantage of economies of scale. But this results in needing to use complex software which makes recovery testing quite a challenge. Before a recovery test can be carried out, the software recovery tester has to make sure that recovery analysis has been undertaken. A fail over test is designed. The fail over test serves to determine that if a given threshold is reached, can the system allocate extra resources. It also serves to show if, in case of critical failure, a system can distribute resources and continue to operate or recover within a specified time. Consider the example of a server which is reachable but it is not responding as one would expect it to. This is the fail-over cause. The result of this, known as the possible impact, could be a crash. The severity of the impact is medium to high. To simulate this one could initiate wrong responses on the server side. Another example of a fail-over cause is a power supply failure. If the failure was in the auxiliary power source its possible impact could be a complete shutdown. This is critical. To simulate this the system could be subjected to a change in power strength or the power cord could simply be unplugged. A low impact severity example includes a DB overload. This could result in slow response time. It could also result in information not being fetched from the DB leading to an error. Using appropriate tools a load test could be created to simulate this scenario. At times a service might stop posing a low to high impact severity depending on the service which stopped. There might not be any possible impact or an application might stop working. To simulate this one could stop the service manually to see the possible impact. The tester also has to ensure that the test plan and test environment are prepared, information is backed up, the recovery panel has been provided education and a record is kept of the techniques used for recovery. Use of resources and having to deal with unpredictable possibilities makes recovery testing a daunting task, but its benefits are worth the trouble. First, recovery testing improves the system quality. It removes risk since one knows that in case of a failure the system will continue to work. Second, recovery testing results in a staff which is educated to perform recovery failure when need arise. Third, recovery testing also fixes problems and mistakes in a system before it has to go live. Finally, recovery testing shows how important recovery is and raises awareness of the fact that long term business continuity relies heavily on recovery management. In conclusion, recovery testing is used to see how a system behaves when failure occurs. Recovery testing can be a tedious process but shows the efficiency of a recovery plan, educates the staff on how to deal with faults and failures which occur in systems, highlights the importance of recovery at times of crisis to members of the IT and business organizations, and shows how important it is to the long term success of a business to have a recovery strategy in case of a disaster.
About the AuthorDanial Schwartz is a content strategist who sheds light on various engaging and informative topics related to the health IT and Q&A industry. His belief in technology, compliance and cost reduction have opened new horizons for people in the health care industry. He is passionate about topics such as Affordable Care Act, EHR,testing, test automation, and privacy and security of data.
Related Resources |
