The Disciplined DevOps Layer
Categories:
layer,
business operations,
agile,
DAD,
DevOps,
Scrum,
release management,
Data Management,
security
Categories: layer, business operations, agile, DAD, DevOps, Scrum, release management, Data Management, security




|
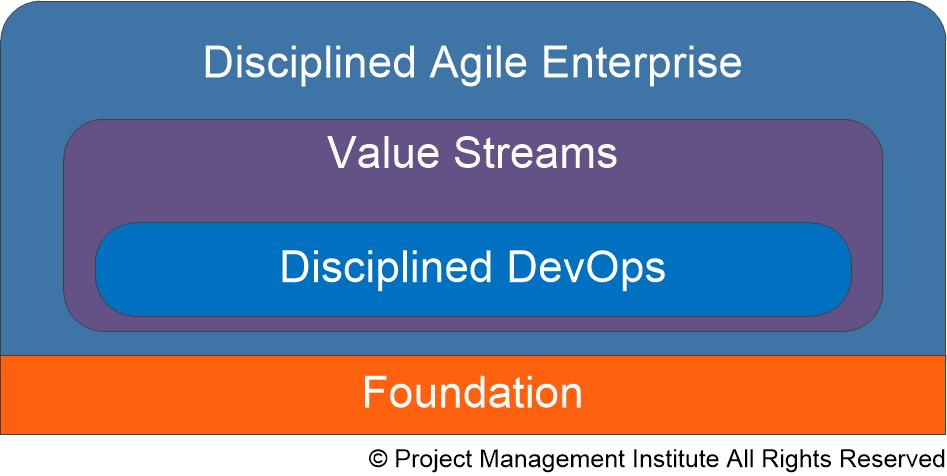
The Disciplined Agile (DA) tool kit is organized into four layers, overviewed in Figure 1. These layers are: Foundation, Disciplined DevOps, Value Streams, and Disciplined Agile Enterprise (DAE). This blog focuses on the Disciplined DevOps layer. Figure 1. The layers of the DA tool kit.
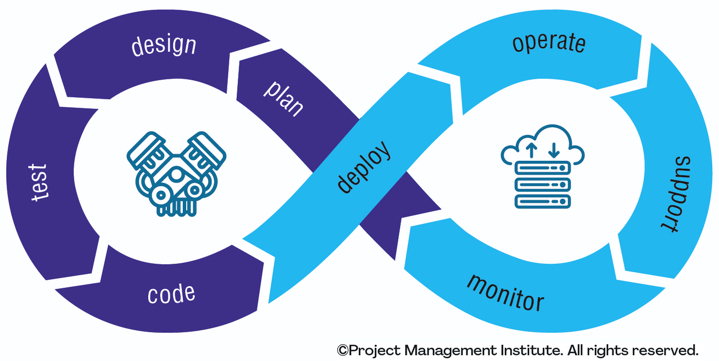
How is "Disciplined DevOps" different from normal/mainstream DevOps? Mainstream DevOps is the streamlining of software development, information technology (IT) operations, and support. This strategy is often depicted as an infinite loop as you see in Figure 2. Disciplined DevOps is an enterprise-ready approach that extends mainstream DevOps to include critical activities around security, data management, release management, and business operations. The high-level workflow for Disciplined DevOps is depicted in Figure 3. Figure 2. The classic DevOps workflow.
Figure 3. The workflow of Disciplined DevOps.
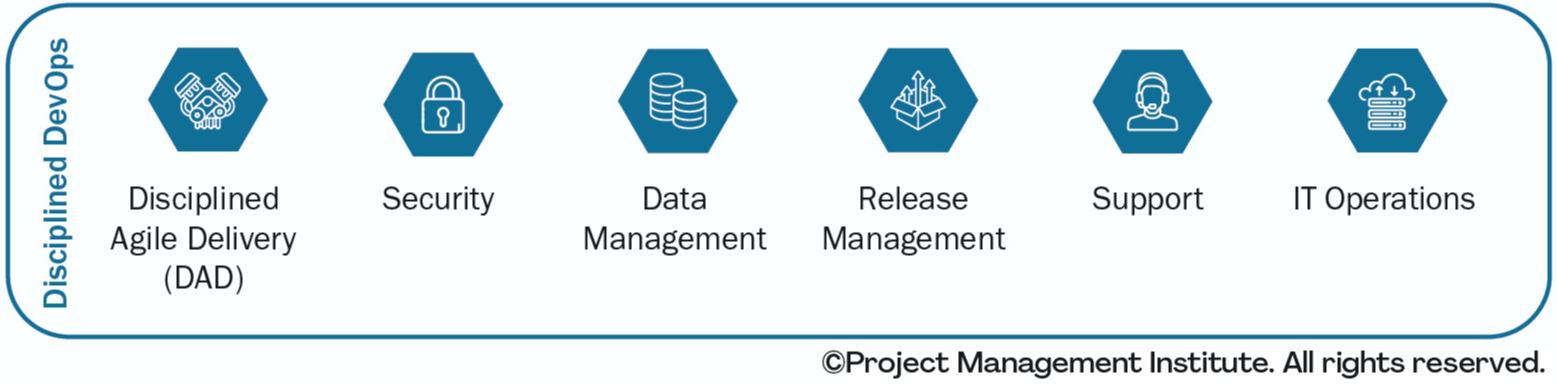
Let's explore the components of Disciplined DevOps. The hexes in Figure 3 represent process blades, sometimes called process areas. A process blade encompasses a cohesive collection of process options, such as practices and strategies, that should be chosen and then applied in a context sensitive manner. Process blades also address functional roles specific to that domain as well as extensions to the DA mindset specific to that domain. The process blades of Disciplined DevOps are:
Disciplined Agile Delivery (DAD)Disciplined Agile Delivery (DAD) is a people-first, learning-oriented hybrid approach to solution delivery. DAD teams focus on the creation of a new, or evolution of an existing, consumable solution for their customers. A solution may include any combination of software, physical assets (e.g. hardware), documentation, changes to the supported business process, and changes to the organizational structure(s) of the people involved. A solution is consumable when it is usable, desirable, and functional. DAD enables a flexible way of working (WoW), supporting several lifecycles in a manner that is tactically scalable. SecurityThe Security process blade focuses on how to protect your organization from both information/virtual and physical threats. This includes procedures for security governance, identity and access management, security policy management, incident response, and vulnerability management. As you would expect these policies will affect your organization’s strategies around change management, disaster recovery and business continuity, solution delivery, and vendor management. For security to be effective it has to be a fundamental aspect of your organizational culture. Data ManagementData management is the development, execution and supervision of plans, policies, programs and practices that control, protect, deliver and enhance the value of data and information assets. DA promotes a pragmatic, streamlined approach to data management that fits into the rest of your organizational processes – we need to optimize the entire workflow, not sub-optimize our data management strategy. Disciplined agile data management does this in an evolutionary and collaborative manner, via concrete data management strategies that provide the right data at the right time to the right people. Release ManagementThe release management process blade encompasses planning, coordinating, and verifying the deployment of solutions into production. Release management requires collaboration by the team(s) producing the solutions and the people responsible for your organization’s operational environment(s). In the case of organizations with a “you build it, you run it” DevOps mindset these people may be one in the same, although even in these situations you will often find a group of people responsible for governing the overall release management effort. In a true DevOps environment release management is fully automated for the intangible aspects (e.g. software and supporting documentation), and perhaps even some physical aspects, of your solution. SupportSupport focuses on helping customers/end users to work with the solutions produced by your delivery teams. Ideally your solutions should be designed so well that people don’t need anyone to help them but unfortunately it doesn’t always work out that way. So in many ways your support strategy is your “last line of defense” in your efforts to Delight Customers. Support goes by many names, including help desk, customer support, and customer care. IT OperationsThe primary aim of IT operations is to run a trustworthy IT ecosystem. From the point of view of your customers, you want to do such a good job that they don’t even notice IT. For older organizations this can be a challenge due to the existence of hundreds, if not thousands, of legacy systems that have been deployed over the decades. You may face daunting technical debt in these systems – poor quality data, overly complex or poorly written source code, systems with inadequate automated regression tests (if any), different versions of the same system, several systems offering similar functionality, numerous technology platforms, systems and technologies for which you have insufficient expertise, and more. Business OperationsBusiness operations is one of the process blades of the value stream layer, although as you see in Figure 3 it is a critical component of the Disciplined DevOps workflow. Business operations focuses on the activities required to provide services to customers and to support your products. The implementation of business operations will vary by value stream, in a bank retail account services is implemented in a very different manner than brokerage services for example. Business operations includes help desk and support services (integrated in with IT support where appropriate) as well as any technical sales support activities such as training, product installation, and product customization. As you can imagine close collaboration with both your Sales and Marketing efforts is required to successfully Delight Customers. |

Information Security: You Have Choices
|
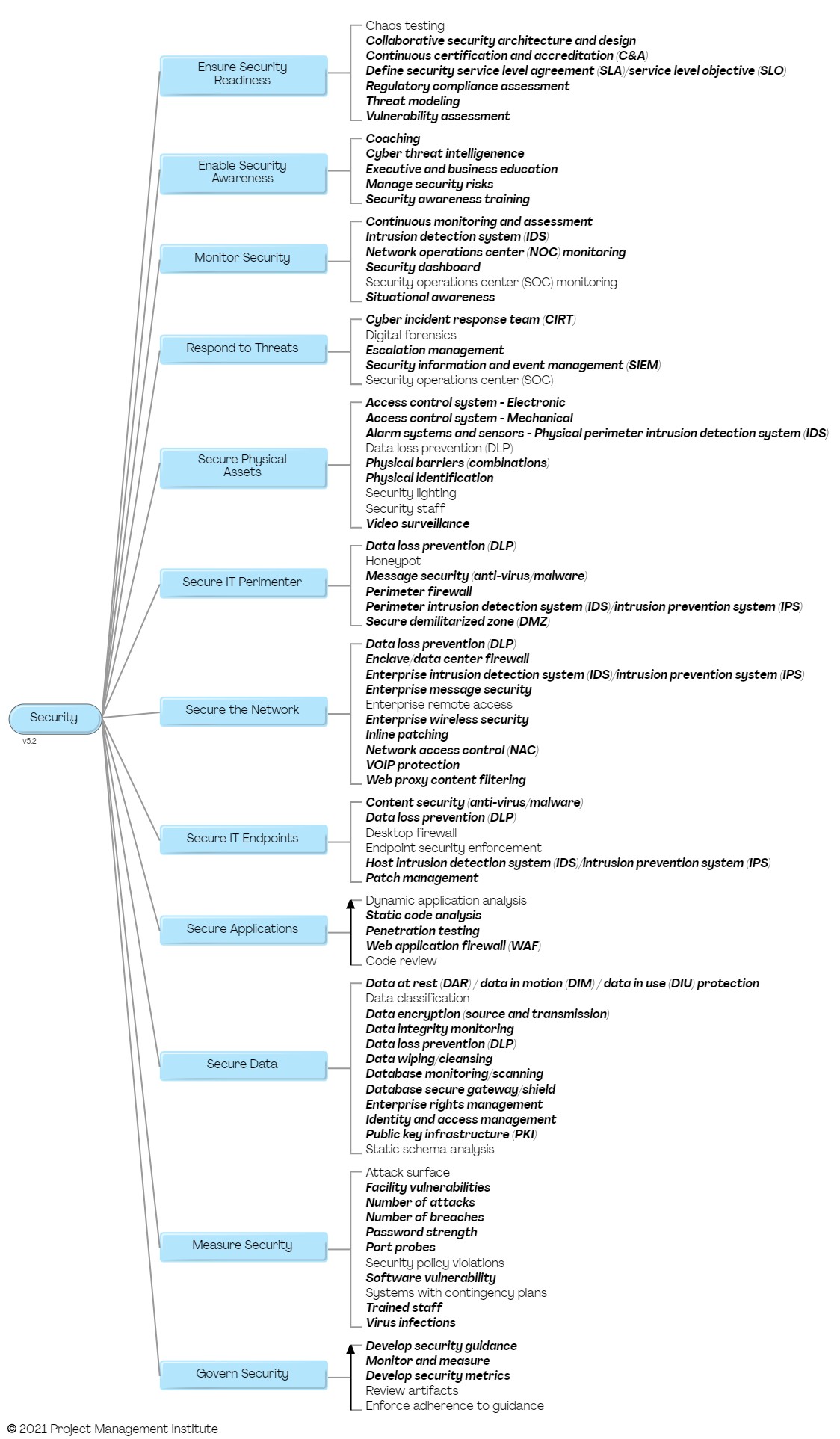
Security is one of the process blades of Disciplined DevOps. The focus of the Security process blade is to describe how to protect your organization from both information/virtual and physical threats. This includes procedures for security governance, identity and access management, vulnerability management, security policy management, incident response, and vulnerability management. As you would expect these policies will affect your organization’s strategies around change management, disaster recovery and business continuity, solution delivery, and vendor management. For security to be effective it has to be a fundamental aspect of your organizational culture. The following process goal diagram overviews the potential activities associated with disciplined agile security. These activities are performed by, or at least supported by, your security (often called an information security or infosec) team. Figure 1. The Security process goal diagram (click to enlarge).
The process factors that you need to consider for implementing effective security are:
Further Reading
|

Database DevOps at Agile 2018
|
On Tuesday, August 7 I facilitated a workshop about Database DevOps at the Agile 2018 conference in San Diego. I promised the group that I would write up the results here in the blog. This was an easy promise to make because I knew that we’d get some good information out of the participants and sure enough we did. The workshop was organized into three major sections:
Overview of Disciplined DevOpsWe started with a brief overview of Disciplined DevOps to set the foundation for the discussion. The workflow for Disciplined DevOps is shown below. The main message was that we need to look at the overall DevOps picture to be successful in modern enterprises, that it was more that Dev+Ops. Having said that, our focus was on Database DevOps.
Challenges around Database DevOpsWe then ran a From/To exercise where we asked people to identify what aspects of their current situation that they’d like to move away from and what they’d like to move their organization towards. The following two pictures (I’d like to thank Klaus Boedker for taking all of the following pics) show what we’d like to move from/to respectively (click on them for a larger version).
I then shared my observations about the challenges with Database DevOps, in particular the cultural impedance mismatch between developers and data professionals, the quality challenges we face regarding data, the lack of testing culture and knowledge within the data community, and the mistaken belief that it’s difficult to evolve production data source.
Techniques Supporting Database DevOpsThe heart of the workshop was to explore technical techniques that support database DevOps. I gave an overview of several Agile Data techniques so as give people an understanding of how Database DevOps works, then we ran an exercise. In the exercise each table worked through one of six techniques (there are several supporting techniques that the groups didn’t work through), exploring:
Each team was limited to their top three answers to each of those questions, and each technique was covered by several teams. Each of the following sections has a paragraph describing the technique, a picture of the Strategy Canvas the participants created, and my thoughts on what the group produced. It’s important to note that the some of the answers in the canvases contradict each other because each canvas is the amalgam of work performed by a few teams, and each of the teams may have included people completely new to the practice/strategy they were working through.
Vertical SlicingJust like you can vertically slice the functional aspects of what you’re building, and release those slices if appropriate, you can do the same for the data aspects of your solution. Many traditional data professionals don’t know how to do this, in most part because traditional data techniques are based on waterfall-style development where they’ve been told to think everything through up front in detail. The article Implementing a Data Warehouse via Vertical Slicing goes into this topic in detail.
The advantages of vertical slicing is that it enables you to get something built and into the hands of stakeholders quickly, thereby reducing the feedback cycle. The challenge with it is that you can lose sight of the bigger picture (therefore you want to do some high-level modeling during Inception to get a handle on the bigger picture). To be successful at vertically slicing your work, you need to be able to incrementally model, or better yet agilely model, and implement that functionality.
Agile Data ModelingThere’s nothing special about data modelling, you can perform it in an agile manner just like you can model other things in an agile manner. Once again, this is a critical skill to learn and can be challenging for traditional data professionals due to their culture around heavy “big design up front (BDUF)”. The article Agile Data Modelling goes into details, and more importantly an example, for how to do this.
Database RefactoringA database refactoring is a simple change to your database that improves the quality of its design without changing the semantics of the design (in a practical manner). This is a key technique because it enables you to safely evolve your database schema, just like you can safely evolve your application code. Many traditional data professionals believe that it is very difficult and risky to refactor a database, hence their penchant for heavy up-front modeling, but this isn’t actually true in practice. To understand this, see the article The Process of Database Refactoring which summarizes material from the award-winning book Refactoring Databases.
Automated Database Regression TestingIf data is a corporate asset then it should be treated as such. Having an automated regression test suite for a data source helps to ensure that the functionality and the data within a database conforms to the shared business rules and semantics for it. For more information, see the article Database Testing.
Continuous Database IntegrationDatabase changes, just like application code changes, should be brought into your continuous integration (CI) strategy. It is a bit harder to include a data source because of the data. The issue is side effects from tests – in theory a database test should put the db into a known state, do something, check to see if you get the expected results, then put the DB back into the original state. It’s that last part that’s the problem because all it takes is one test to forget to do so and there’s the potential for side effects across tests. So, a common thing is to rebuild (or restore, or a combination thereof) your dev and test data bases every so often so as to decrease the chance of this. You might choose to do this in your nightly CI run for example. For more information, see the book Recipes for Continuous Database Integration. Operational Data Monitoring An important part of Operations is to monitor the running infrastructure, including databases. This information can and should be available via real-time dashboards as well as through ad-hoc reporting. Sadly, I need to write an article on this still. But if you poke around the web you’ll find a fair bit of information. Article to come soon.
Concluding ThoughtsThis was a really interesting workshop. We did it in 75 minutes but it really should have been done in a half day to allow for more detailed discussions about each of the techniques. Having said that, I had several very good conversations with people following the workshop about how valuable and enlightening they found it. This workshop, plus other training and service offerings around agile database and agile data warehousing skills, is something that we can provide to your organization. Feel free to reach out to us. |

.png)








Database DevOps at Agile 2018
|
On Tuesday, August 7 I facilitated a workshop about Database DevOps at the Agile 2018 conference in San Diego. I promised the group that I would write up the results here in the blog. This was an easy promise to make because I knew that we’d get some good information out of the participants and sure enough we did. The workshop was organized into three major sections:
Overview of Disciplined DevOpsWe started with a brief overview of Disciplined DevOps to set the foundation for the discussion. The workflow for Disciplined DevOps is shown below. The main message was that we need to look at the overall DevOps picture to be successful in modern enterprises, that it was more that Dev+Ops. Having said that, our focus was on Database DevOps.
Challenges around Database DevOpsWe then ran a From/To exercise where we asked people to identify what aspects of their current situation that they’d like to move away from and what they’d like to move their organization towards. The following two pictures (I’d like to thank Klaus Boedker for taking all of the following pics) show what we’d like to move from/to respectively (click on them for a larger version).
I then shared my observations about the challenges with Database DevOps, in particular the cultural impedance mismatch between developers and data professionals, the quality challenges we face regarding data, the lack of testing culture and knowledge within the data community, and the mistaken belief that it’s difficult to evolve production data source.
Techniques Supporting Database DevOpsThe heart of the workshop was to explore technical techniques that support database DevOps. I gave an overview of several Agile Data techniques so as give people an understanding of how Database DevOps works, then we ran an exercise. In the exercise each table worked through one of six techniques (there are several supporting techniques that the groups didn’t work through), exploring:
Each team was limited to their top three answers to each of those questions, and each technique was covered by several teams. Each of the following sections has a paragraph describing the technique, a picture of the Strategy Canvas the participants created, and my thoughts on what the group produced. It’s important to note that the some of the answers in the canvases contradict each other because each canvas is the amalgam of work performed by a few teams, and each of the teams may have included people completely new to the practice/strategy they were working through.
Vertical SlicingJust like you can vertically slice the functional aspects of what you’re building, and release those slices if appropriate, you can do the same for the data aspects of your solution. Many traditional data professionals don’t know how to do this, in most part because traditional data techniques are based on waterfall-style development where they’ve been told to think everything through up front in detail. The article Implementing a Data Warehouse via Vertical Slicing goes into this topic in detail.
The advantages of vertical slicing is that it enables you to get something built and into the hands of stakeholders quickly, thereby reducing the feedback cycle. The challenge with it is that you can lose sight of the bigger picture (therefore you want to do some high-level modeling during Inception to get a handle on the bigger picture). To be successful at vertically slicing your work, you need to be able to incrementally model, or better yet agilely model, and implement that functionality.
Agile Data ModelingThere’s nothing special about data modelling, you can perform it in an agile manner just like you can model other things in an agile manner. Once again, this is a critical skill to learn and can be challenging for traditional data professionals due to their culture around heavy “big design up front (BDUF)”. The article Agile Data Modelling goes into details, and more importantly an example, for how to do this.
Database RefactoringA database refactoring is a simple change to your database that improves the quality of its design without changing the semantics of the design (in a practical manner). This is a key technique because it enables you to safely evolve your database schema, just like you can safely evolve your application code. Many traditional data professionals believe that it is very difficult and risky to refactor a database, hence their penchant for heavy up-front modeling, but this isn’t actually true in practice. To understand this, see the article The Process of Database Refactoring which summarizes material from the award-winning book Refactoring Databases.
Automated Database Regression TestingIf data is a corporate asset then it should be treated as such. Having an automated regression test suite for a data source helps to ensure that the functionality and the data within a database conforms to the shared business rules and semantics for it. For more information, see the article Database Testing.
Continuous Database IntegrationDatabase changes, just like application code changes, should be brought into your continuous integration (CI) strategy. It is a bit harder to include a data source because of the data. The issue is side effects from tests – in theory a database test should put the db into a known state, do something, check to see if you get the expected results, then put the DB back into the original state. It’s that last part that’s the problem because all it takes is one test to forget to do so and there’s the potential for side effects across tests. So, a common thing is to rebuild (or restore, or a combination thereof) your dev and test data bases every so often so as to decrease the chance of this. You might choose to do this in your nightly CI run for example. For more information, see the book Recipes for Continuous Database Integration. Operational Data Monitoring An important part of Operations is to monitor the running infrastructure, including databases. This information can and should be available via real-time dashboards as well as through ad-hoc reporting. Sadly, I need to write an article on this still. But if you poke around the web you’ll find a fair bit of information. Article to come soon.
Concluding ThoughtsThis was a really interesting workshop. We did it in 75 minutes but it really should have been done in a half day to allow for more detailed discussions about each of the techniques. Having said that, I had several very good conversations with people following the workshop about how valuable and enlightening they found it. This workshop, plus other training and service offerings around agile database and agile data warehousing skills, is something that we can provide to your organization. Feel free to reach out to us. |
Building Your IT Support Environment
| An important aspect of Support that is easily forgotten is the need to build out your infrastructure to enable your support efforts. This may include:
Figure 1. High-level architecture for a Support environment (click on it for larger version). |
